미래연구소 홈페이지: https://futurelab.creatorlink.net/
CNN의 활용 분야

CNN은 Image classification에 특화되어 있으며, object detection, segmentation등에 활용이 된다. 뿐만아니라 Neural Styler Transfer, NLP 등에도 활용이 될 수 있다.

CNN은 인간이 시각자극을 처리하는 방법에서 모티브를 얻어 만들어졌다. 뇌는 특정 feature를 detect하는데 활성화되는 뉴런이 다 다르다. (직선 모양을 인지하는 뉴런과 점을 인지하는 뉴런이 다르다) 그리고 인접 정보를 읽으며 공간 정보를 계층적으로 학습한다.

기존의 Fully-Connected Layer를 이용하게 되면 두 가지 문제점이 생긴다. 첫번째는 이미지를 평행이동했을 때 동일한 이미지로 인식하지 못하고, 두 번째는 모든 pixel의 feature를 추출하기 때문에 비효율적이라는 점이다.
CNN은 특정 feature마다 kernel을 통해 인접한 feature 단위를 계층적으로 학습한다. 그리고 convolution 연산이 평행이동과 데이터 과다에 대한 문제를 해결해준다.
Convolution 연산

예를 들어 위와 같은 5x5 pixel이 있다고 하자. 검정색 타일이 1, 흰색 타일이 0이라면 이 이미지를 숫자로 변환햇을 때는 아래와 같이 된다.

이제 여기서 Convolution 연산을 이용해서 아래 그림처럼 대각선 feature가 있는지 찾아보자.
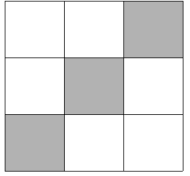
이 찾고자 목표하는 3x3 이미지는 kernel(filter)라고 하며, 이는 숫자로 나타내면 아래와 같다.

이제 convolution연산을 통해 filter와 일치하는 부분이 있는지 탐색한다. 3x3 element wise product를 filter를 한칸씩 옮기면서 수행하면 된다. 첫 칸을 예로 들면,


빨간색 숫자가 필터값이고 검은색 숫자가 기존 이미지 값일 때 각 칸의 숫자들을 서로 곱해서 모두 합하면 3이 나온다.
그 후 필터를 한칸씩 이동하면서 연산을 반복하면 총 9번의 연산을 시행할 수 있다.


연산을 마치면 아래와 같은 최종 결과를 얻는다.

이를 Activation map이라 한다. map은 지도이다. 지도는 넓은 땅을 축척으로 압축시켜 놓은 것을 의미한다. 여기서도 마찬가지로 kernel에 해당하는 특징이 얼마만큼 있는지를 압축시켜놓은 것이라고 생각하면 편하다.
이렇게 convolution 연산으로 이미지 특징을 추출하면 filter에 해당하는 만큼만 연산을 하면 되기 때문에 fully-connected 가 아닌 locally-connected가 되어 효율적인 연산을 할 수 있다. 또 filter가 평행이동하면서 연산하므로 평행이동한 이미지도 인식할 수 있다.

Andrew Ng 교수님의 강의에서는 Multiple filter가 어떤식으 적용되는지 설명해주는데, 원본 이미지와 filter의 channel의 수가 일치해야하고, flter의 개수와 최종 activation map의 depth가 같아지는 것을 알 수 있다.
Hyperparameter
Convolution 연산에는 두 가지 hyperparameter가 있는데, 하나는 kernel의 size이고 ekfms gksksms filters이다.
kernel_size는 얼마만한 크기의 필터를 쓸 것인가인데, 보통 홀수 개수를 쓰고 대부분 3X3 필터를 이용한다고 한다. 왜냐하면 현재 위치 pixel에서의 가로세로 대칭만큼과의 관계를 파악하는 것이 convolution 연산의 목적이기 때문이다.
그리고 kernel의 개수는 자신이 설정하기 나름인데, 너무 큰 값을 설정하면 overfitting의 위험이 있으므로 삼가는 것이 좋다.
Other Options: padding, pooling
1) padding: filter 주변에 0으로 감싸서 덩치를 키우는 것을 의미한다. 이또한 hyper parameter로 vaild(default)가 패딩을 주지 않는 것이고 same으로 설정하면 padding으로 outputsize와 inputsize가 같게끔 만들어준다.

2) pooling- MAX POOLING

max pooling을 이용하면 설정한 pool_size안에서 가장 큰 값으로 downsampling 할 수 있다. 이는 필요 없는 정보를 버리는 역할을 한다. 이 때 pool_size는 얼마만큼 크기를 기준으로 downsampling할 건지, stride는 얼마만큼 이동하면서 smpling할건지를 정할 수 있다.
'Deep Learning' 카테고리의 다른 글
| Pandas 기초 1: Series와 DataFrame 다루기 (2) | 2020.09.01 |
|---|---|
| Metrics (0) | 2020.08.31 |
| [Dacon] 공유된 코드를 통해 선수지식 학습하기 (0) | 2020.08.30 |
| [데이콘]Dataset 받아오기 (1) | 2020.08.26 |
| [데이콘]컴퓨터 비전 학습 경진대회에 참가 결정 (0) | 2020.08.23 |
| Normalization, Standardization, Initialization, optimization (1) | 2020.08.18 |
| Softmax, One-hot encoding, Regularization, Dropout의 이해 (0) | 2020.08.15 |
| Deep Learning 미래연구소 5주차 수강후기 (0) | 2020.08.02 |



